We saw in the notes that \(E(s^2) = \sigma^2\). Let’s explore why this might not be the best estimator.
We define the MSE of an estimator \(\theta\) as \(E((\theta - \hat\theta^2)^2)\). For the variance, this is \(E((\sigma^2 - s^2)^2)\).
Let’s simulate a bunch of linear models, calculate the standard deviations, and then calculate this quantity.
We’re going to focus on multiplicative bias, and you’ll see why at the end. This means that we’ll focus on estimators of the form \(as^2\).
Show the code
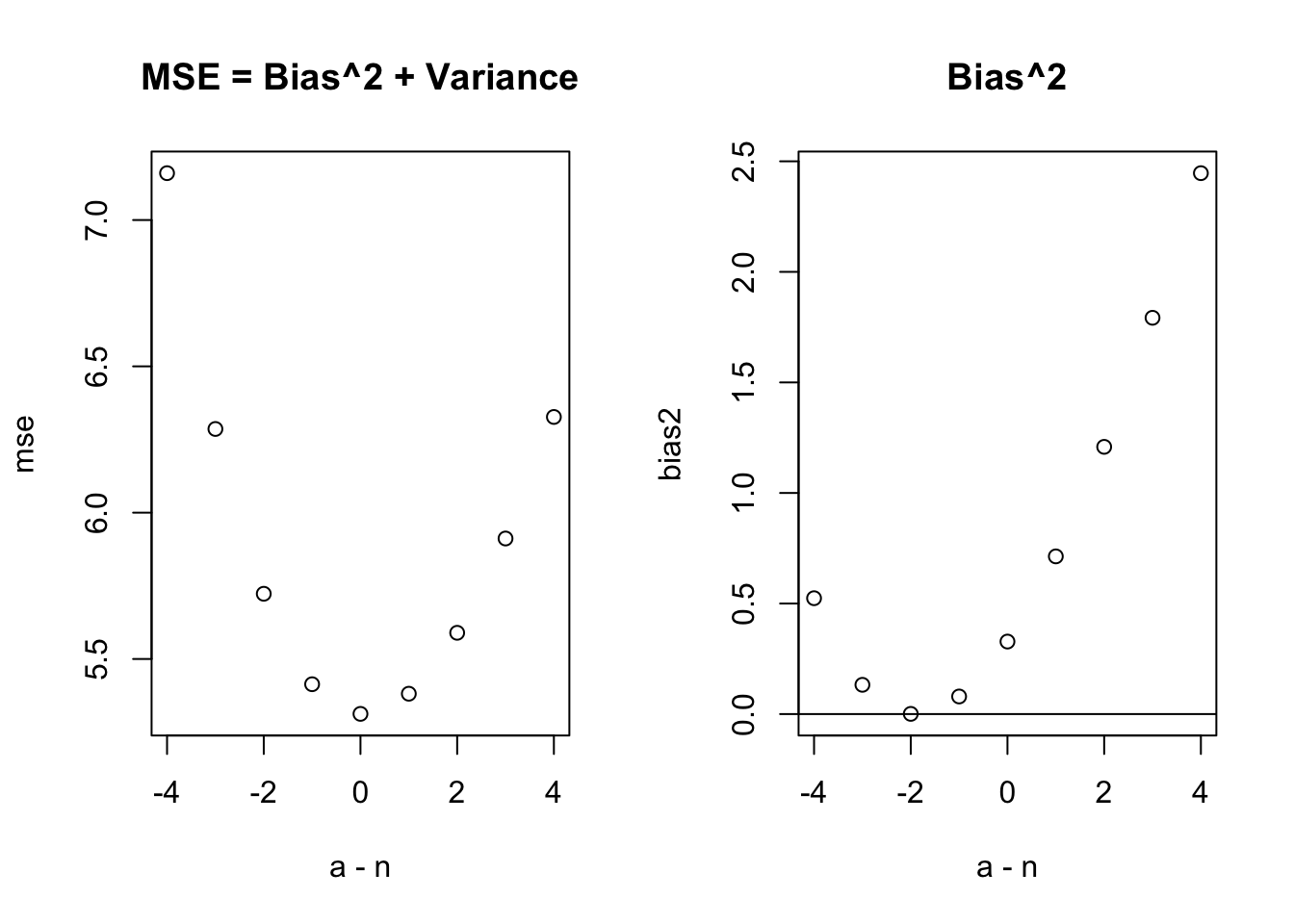
set.seed(2112)n <-30x <-runif(n, 0, 10)beta0 <--3beta1 <--4sigma <-3reps <-1000esst <-double(reps)for (i in1:reps) { y <- beta0 + beta1*x +rnorm(n, 0, sigma) beta1 <-sum((x -mean(x)) * (y -mean(y))) /sum((x -mean(x))^2) beta0 <-mean(y) - beta1 *mean(x) yhat <- beta0 + beta1 * x e <- y - yhat esst[i] <-sum(e^2)}a <- (n-4):(n+4)mse <-double(length(a))bias2 <-double(length(a))for (i inseq_along(a)) { mse[i] <-mean((sigma^2- esst / a[i])^2) bias2[i] <- (sigma^2-mean(esst / a[i]))^2}par(mfrow =c(1,2))plot(a - n, mse, main ="MSE = Bias^2 + Variance")plot(a - n, bias2, main ="Bias^2")abline(h =0)
From these plots, we see that the lowest MSE, i.e. the lowest value of \(E((\sigma^2 - as^2)^2)\), is at \(a = 1/n\). Note that this corresponds to the MLE of \(\sigma^2\). However, this is a biased estimate, and the unbiased estimate occurs at \(a=1/(n-2)\).
What’s happening here? Shouldn’t unbiased be best? Well, yes, if our criteria is minimizing bias! If we want to minimize \(E((\sigma^2 - \hat\sigma^2)^2)\), we have to account for the variance of the estimator across all possible samples as well!
HWK: Modify the code to show that the bias of the constant model (\(\beta_1 = 0\)) is minimized at \(n-1\), with the MSE being minimized at \(n+1\). It’s bizarre, but that’s how it works!
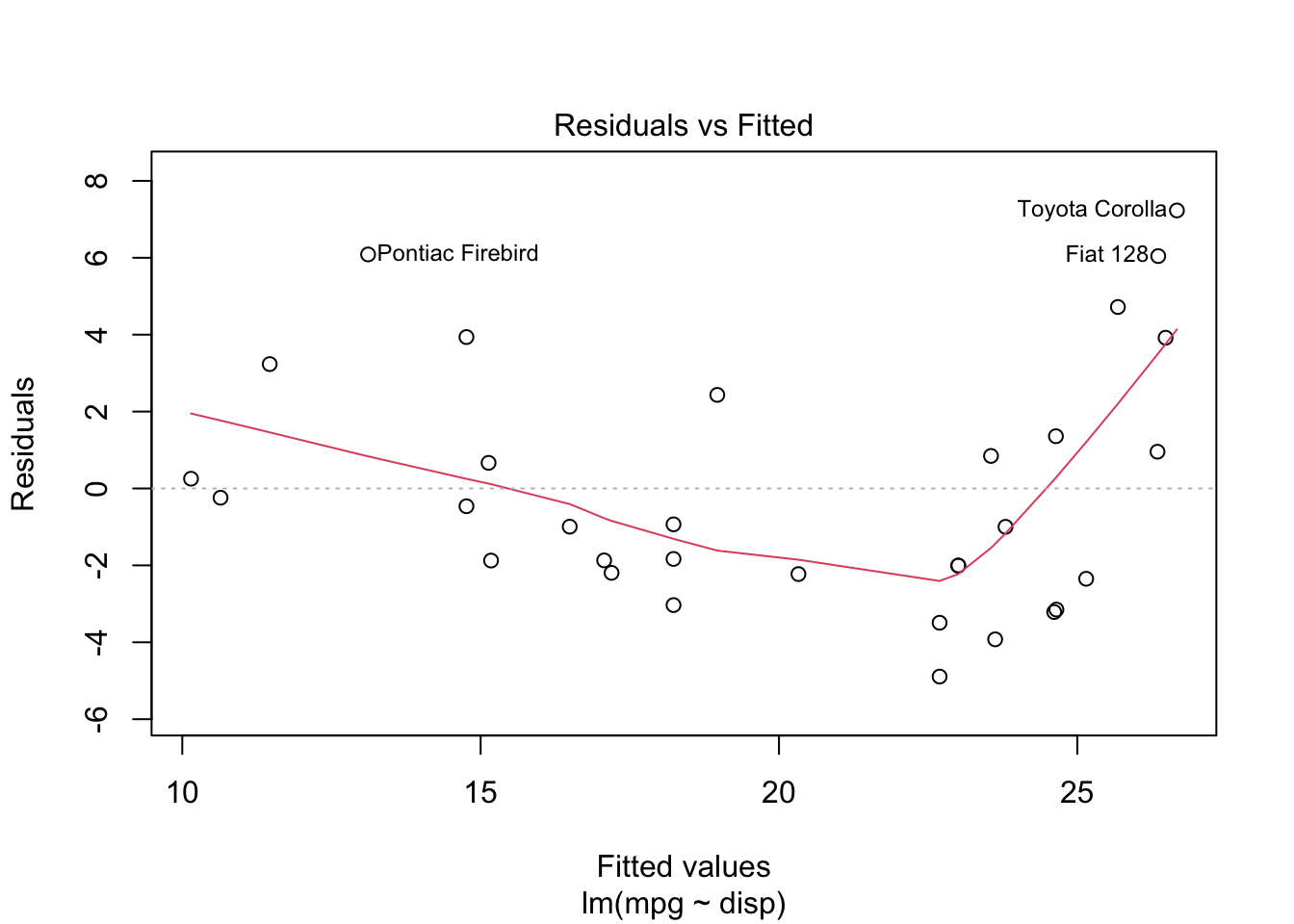
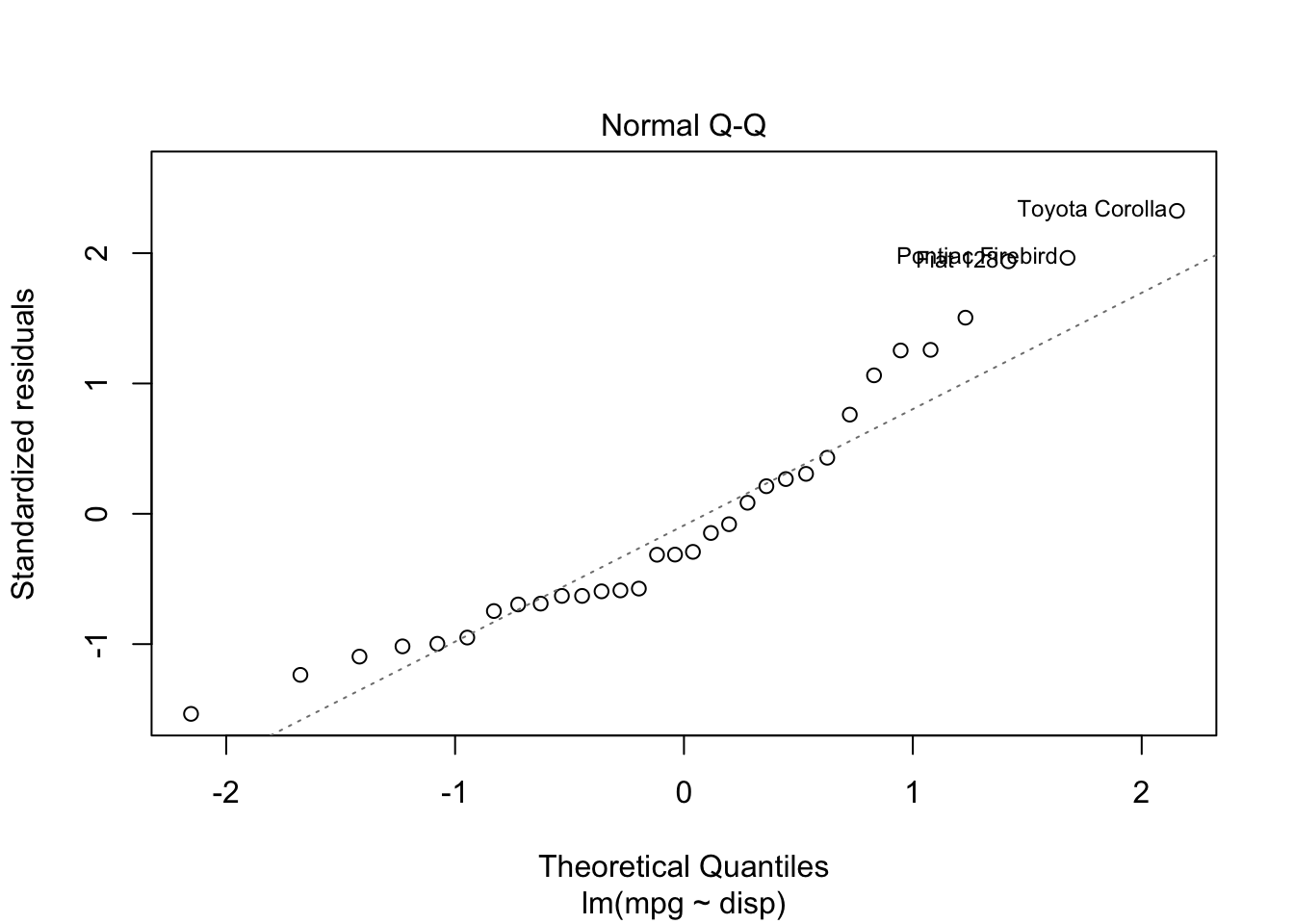
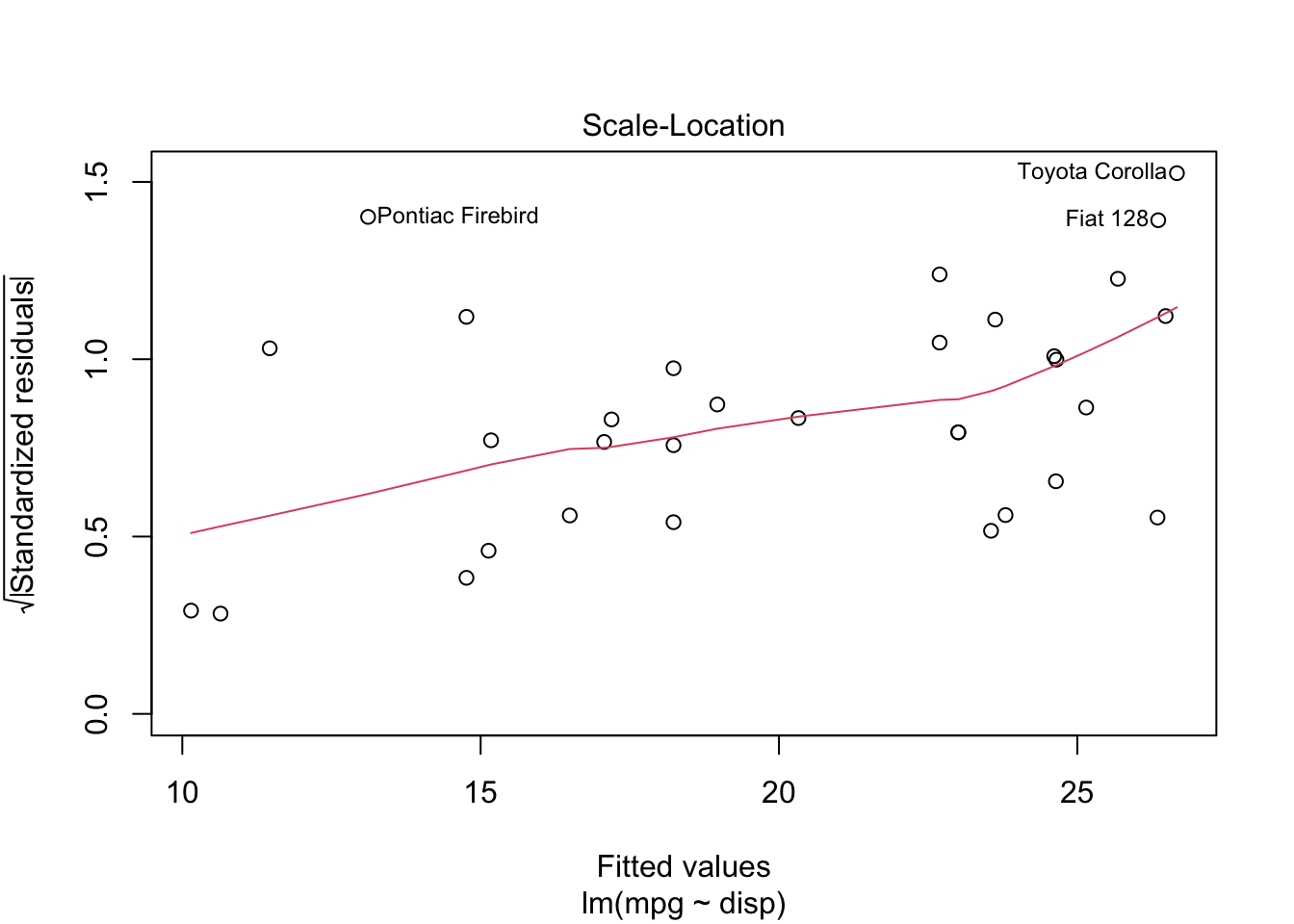
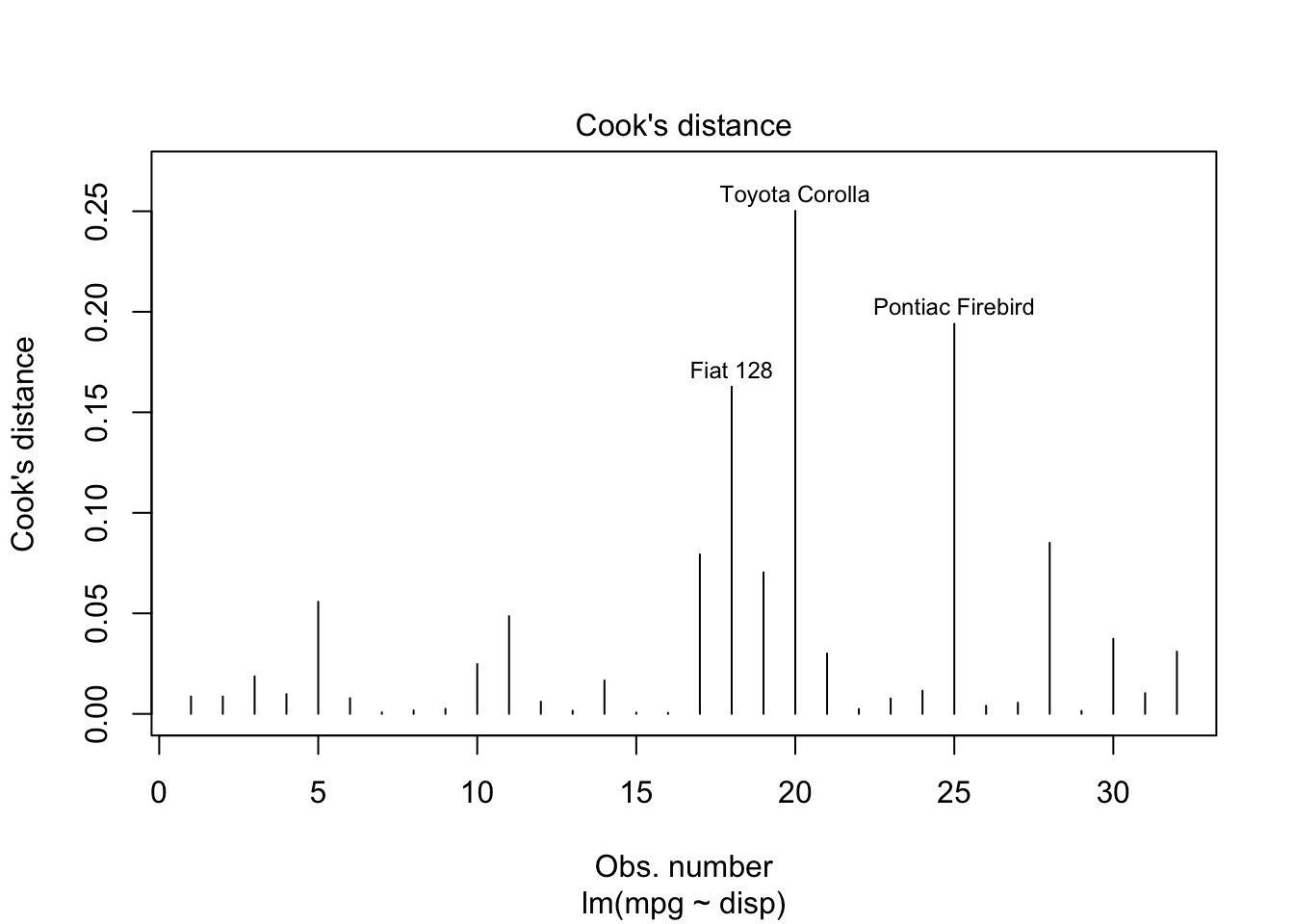
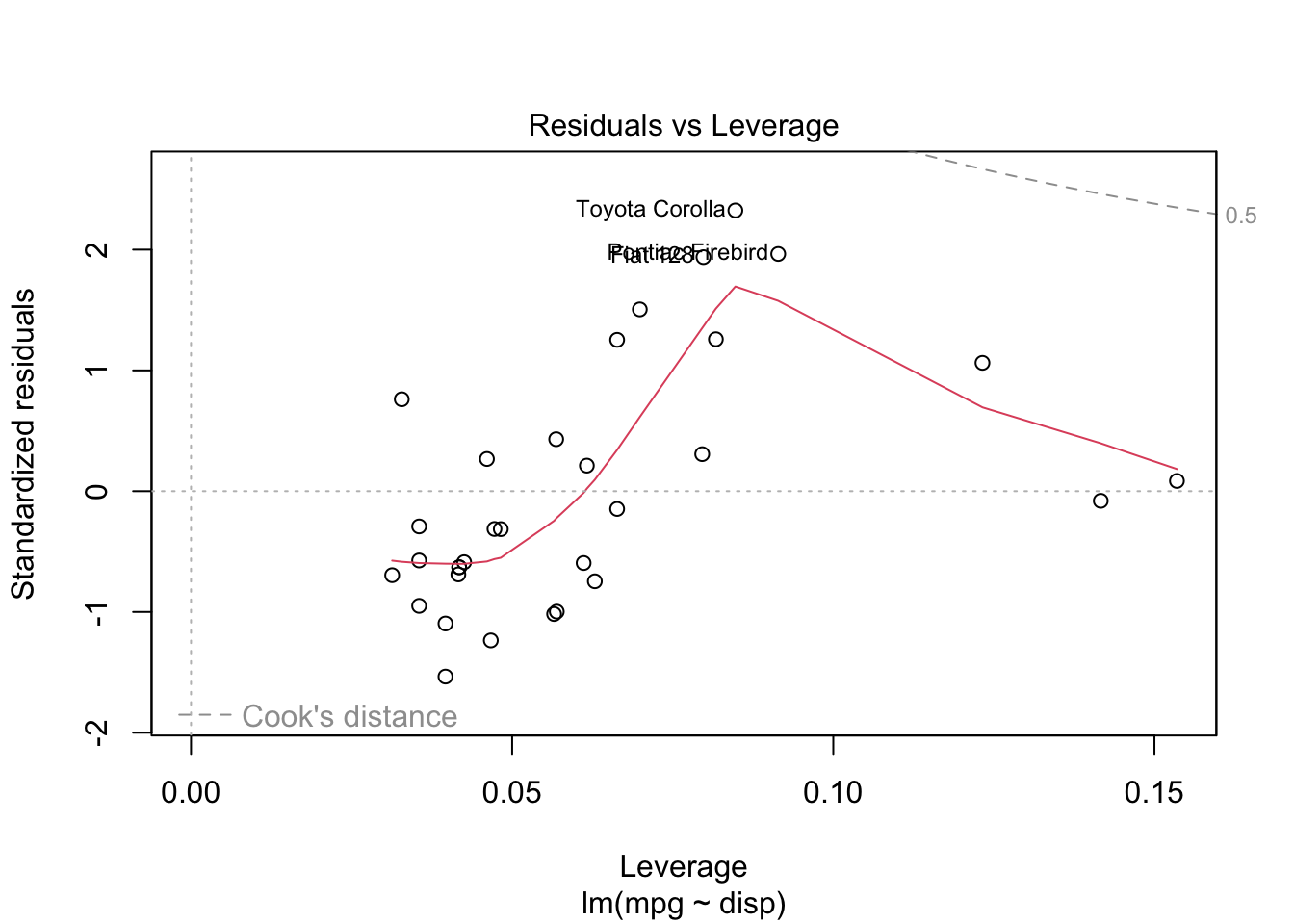
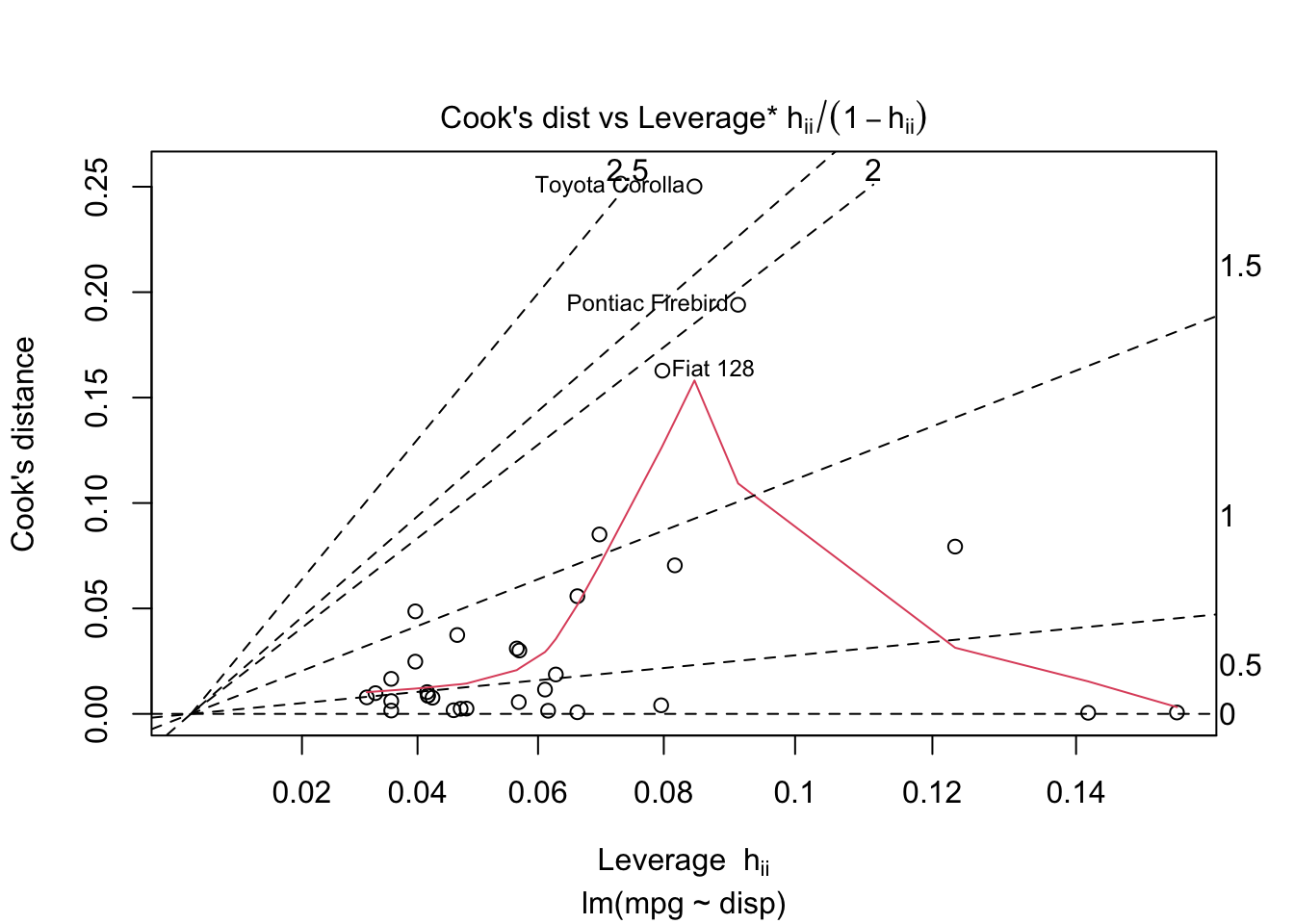
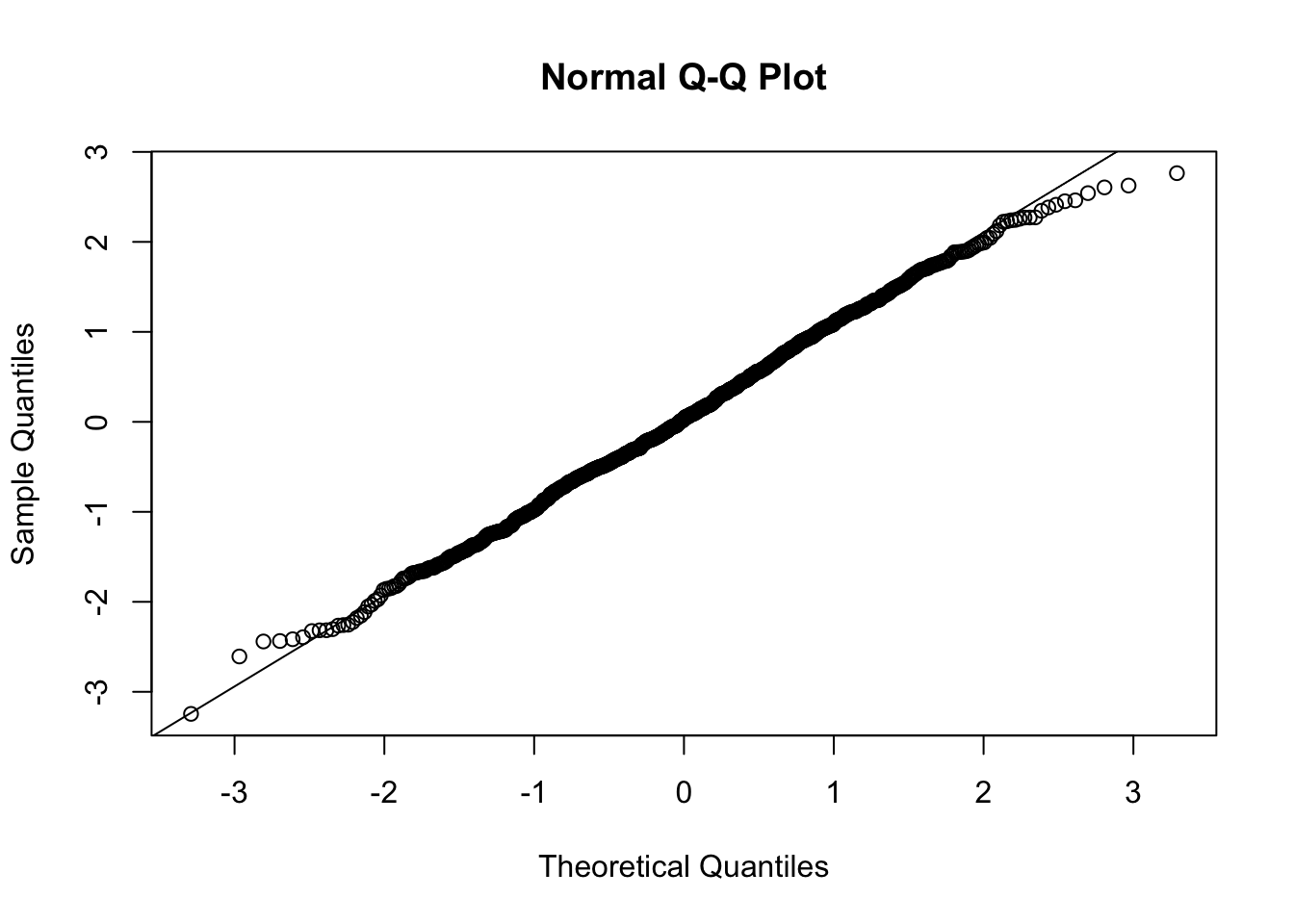
B.2 Residuals
The plot.lm() function makes most of the plots you’ll need.
Show the code
mylm <-lm(mpg ~ disp, data = mtcars)plot(mylm, which=1:6)
The broom package will be very useful in the future. In particular, the augment() function results in a tidy data frame with columns that are very relevant to our analyses.